Golden-Free AI-Assisted Hardware Trojan Detection
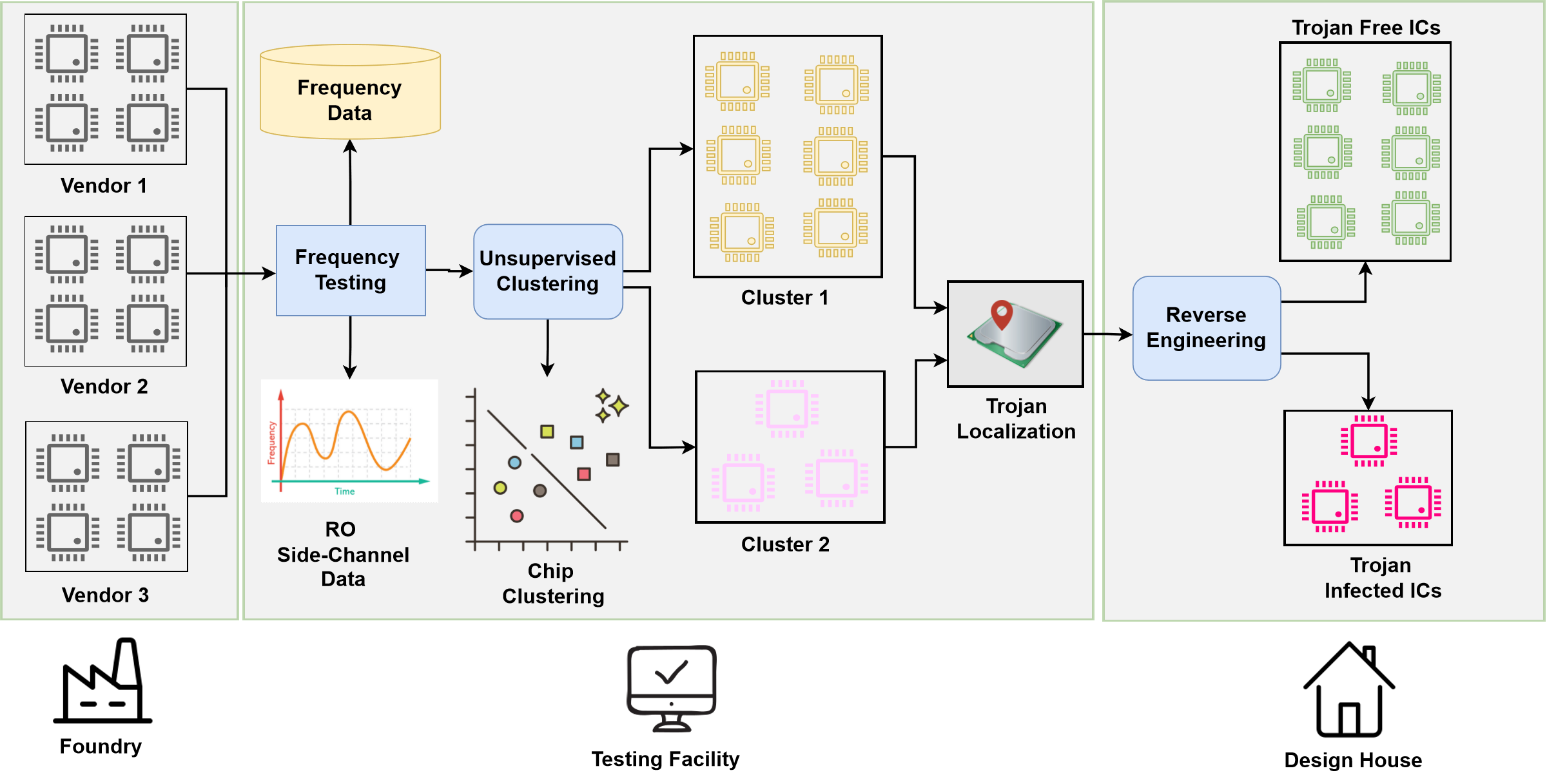
Hardware Trojans are malicious IC modifications that can leak sensitive information, disrupt critical systems, or damage trust in the semiconductor supply chain. Many side-channel detection methods depend on golden reference chips, which are expensive, unavailable, or impractical in outsourced fabrication settings.
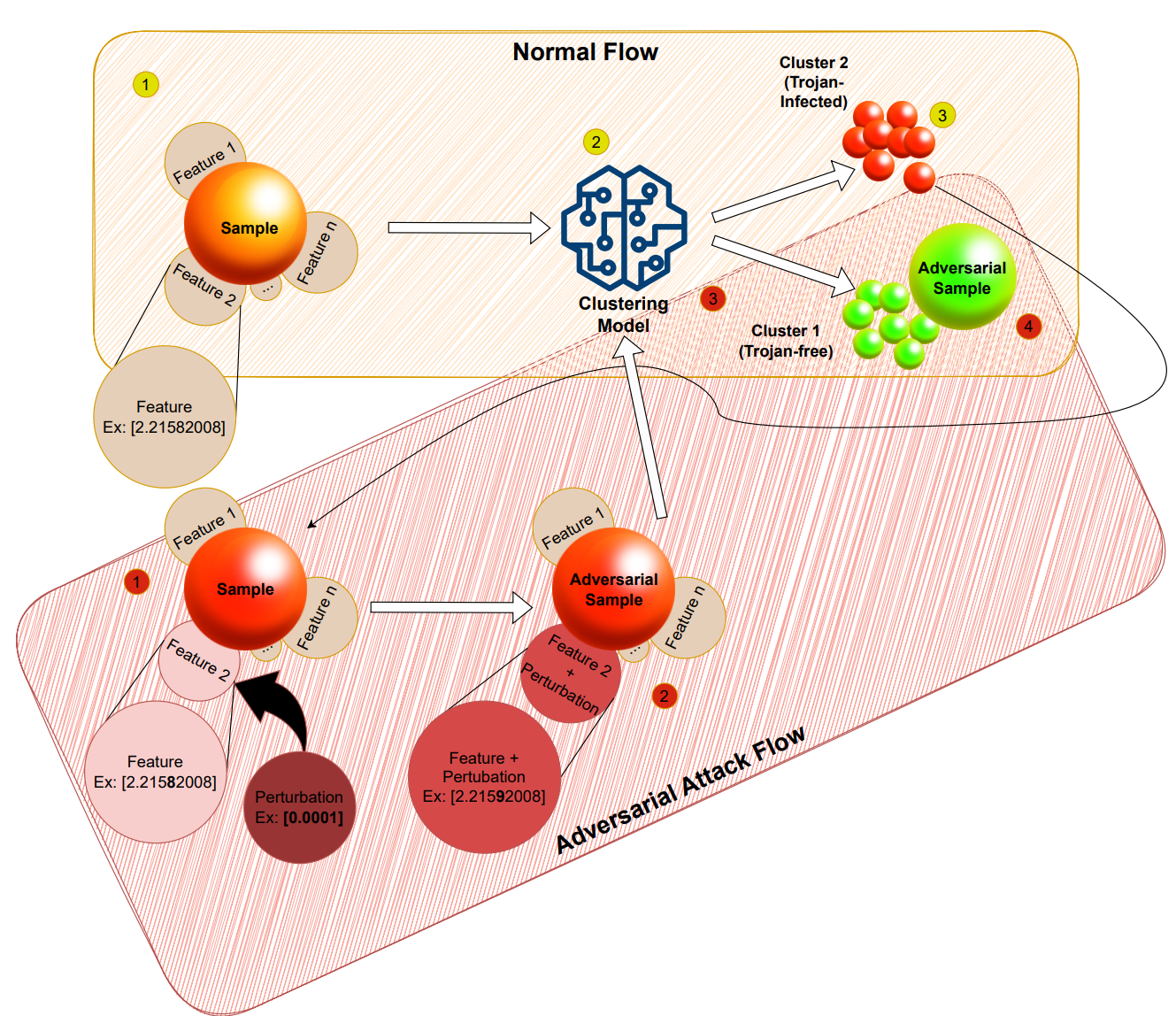
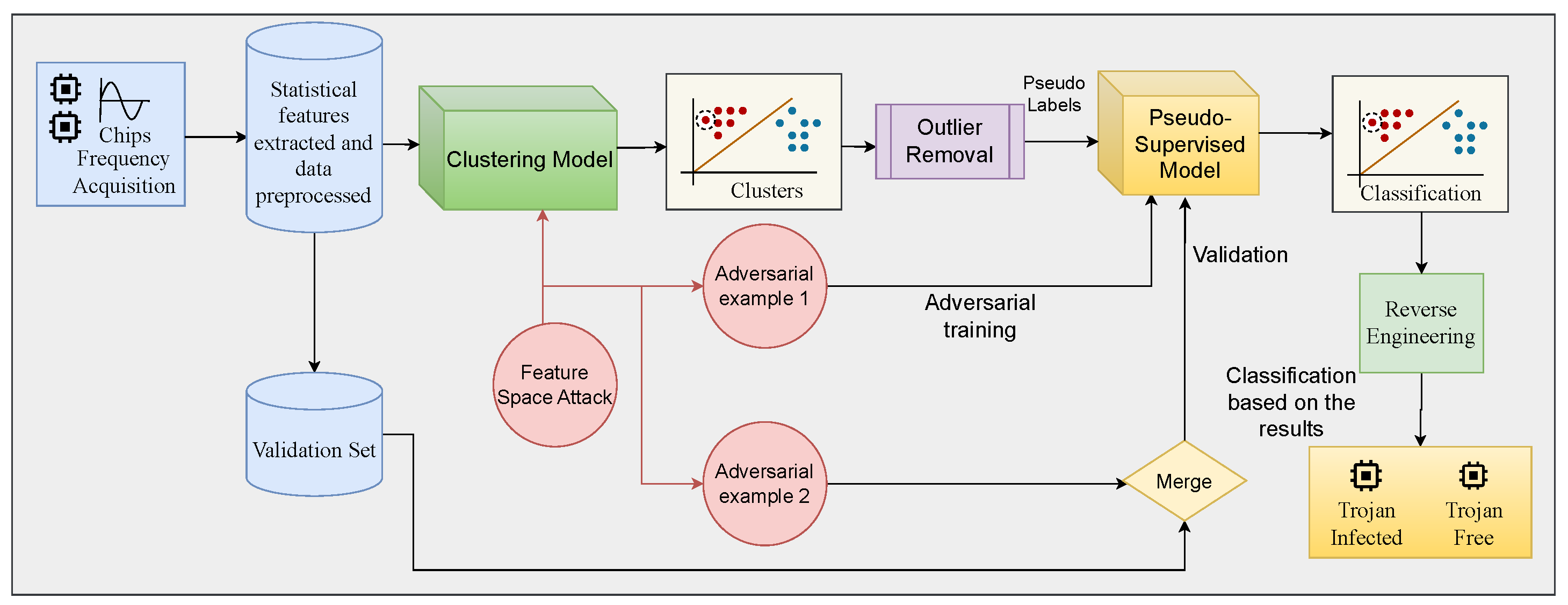
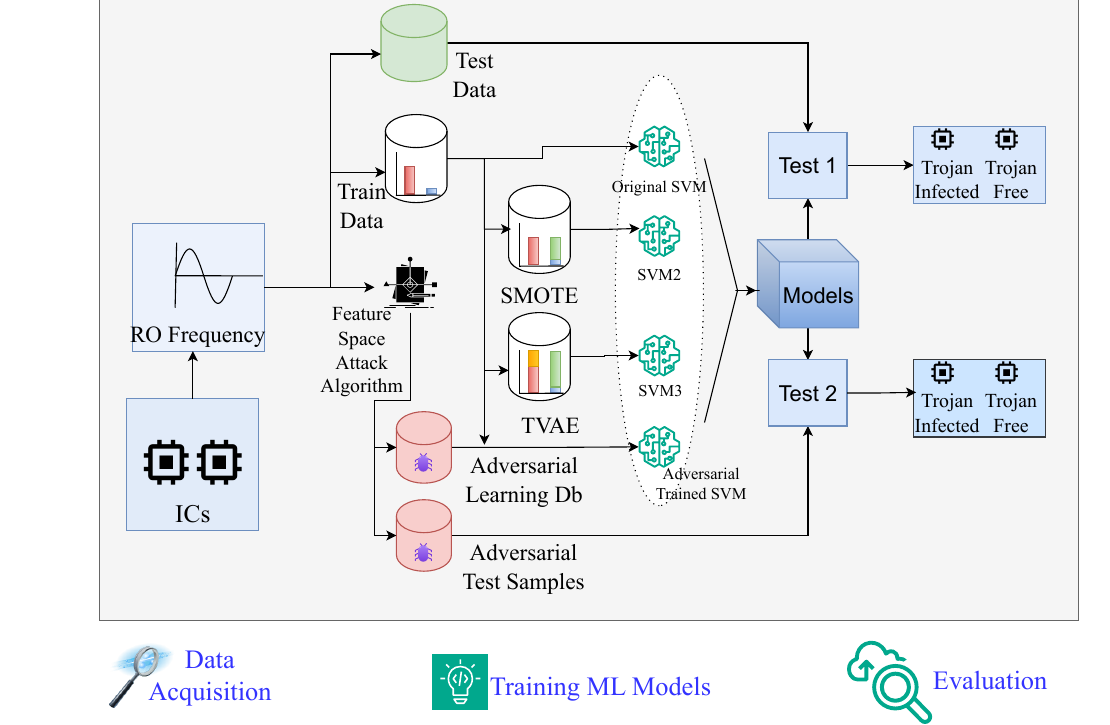
My work uses Ring Oscillator Network side-channel measurements with unsupervised clustering to detect Trojan-affected chips without golden data. The published work demonstrated strong detection behavior for small, short-triggered Trojans, reaching 93% accuracy while keeping the method practical for supply-chain validation.
A related submitted extension combines golden-free clustering with on-chip localization. Instead of only saying that a chip is suspicious, the framework estimates the likely Trojan-affected region so reverse engineering can focus on a smaller part of the die. FPGA validation on MD5 processor prototypes reached 95% accuracy across multiple Trojan sizes and designs.